
昨今、トレンドが目まぐるしく移り変わるフロントエンド。そんなフロントエンドの世界の「イマ気になる企業の取り組みが知りたい!」ということで、6月21日に株式会社オープンエイト様主催の「進化するフロントエンド2021 −4プロダクトから学ぶSPA/PWAの技術と実践−」が開催されました。 本イベントでは4社が登壇し、グッドパッチからは私、古家が登壇させていただきました。このブログでは、私の登壇内容を少し踏み込んだ形でお届けします。イベントでは語りきれなかった裏話や想いも盛り込んでみましたので、ぜひご一読ください。
- 理想とするビジュアルコラボレーションの実現を目指して
- 整合性の担保を目指したLayer1.0
- 机上シミュレーションで共同作業を可能にしたLayer2.0
- データ構造を刷新したLayer3.0
- 体感した、ビジュアルコラボレーションの可能性
- 最後に
理想とするビジュアルコラボレーションの実現を目指して

本題に入る前に自己紹介をさせてください。グッドパッチにて、モバイル/フロントエンドエンジニアを務める古家です。もともとは Androidエンジニアだったのですが、自社サービスのアプリ開発を経て2019年よりオンラインホワイトボードStrapのフロントエンドを中心に担当しています。最近は、要件定義やデザイン、開発プロセスの改善などにもチャレンジしています。 今回のイベントではStrapの「Layerの歴史で振り返る価値創出」についてお話しさせていただきました。
そしてStrapについても少し。Strapは、2020年9月1日に正式版をリリースした“リモートコラボレーションの可能性を広げる”オンラインホワイトボードです。実は、今みなさんにご覧いただいている資料もStrapで作ったものなんです。

特徴としては、無限に広がるボード上でクオリティの高い作図が誰でも作成でき、組織での利用に最適化された機能をご用意している点があります。
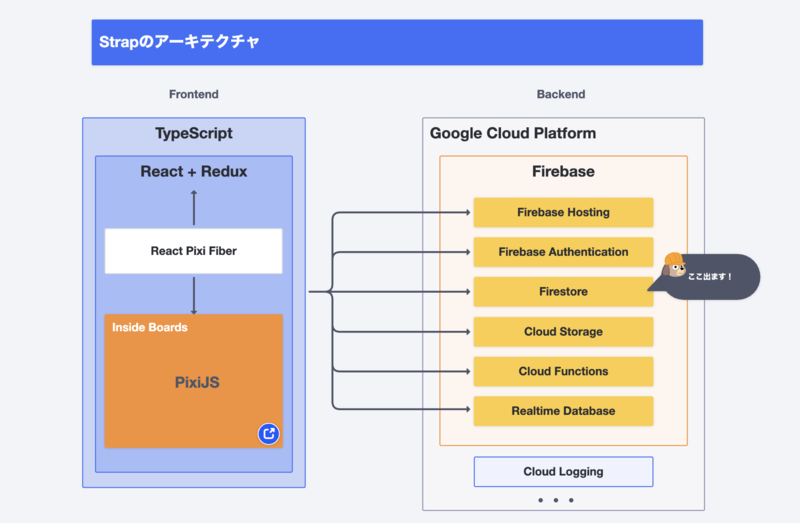
Strapのアーキテクチャについても簡単にご紹介しますね。フロントエンドは、TypeScriptで実装しておりReactとReduxを中心としたフレームワークを利用して構築しています。また、みなさんにご覧いただいているボードに関しては、PixiJSというWebGLのグラフィックエンジンを利用して実装しています。バックエンドはGoogle Cloud Platform (GCP)上に構築しており、主要な機能に関してはFirebaseを利用して構築しています。
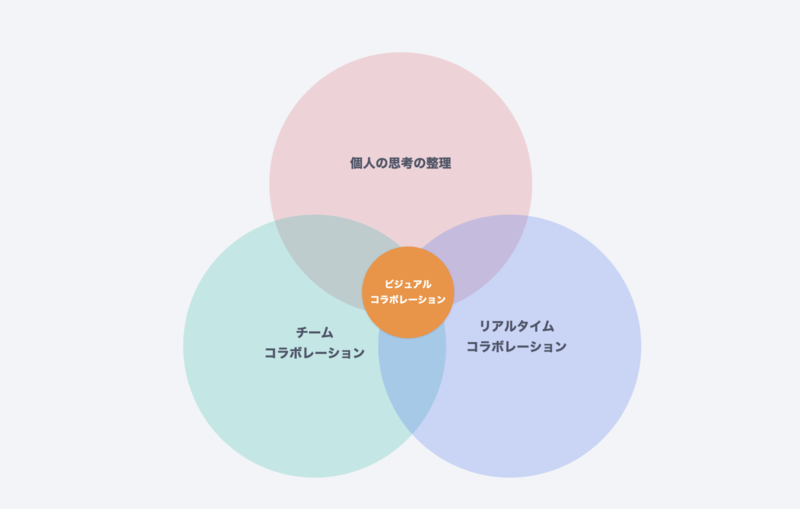
そんなStrapでは、大切にしている3つの価値があります。個人の思考の整理、チームコラボレーション、リアルタイムコラボレーションの3つです。私たちはこの3つの価値を通してビジュアルコラボレーションを実現したいと考えています。
さらに私たちは、Strapの各機能がどんな価値を追求したいのかをより明確にしようと、上の3つの価値をもう少し詳細に言語化した『価値マップ』というものを作りました。初期の開発ロードマップにおいて、機能の開発や開発の優先度を判断する際に活用していました。
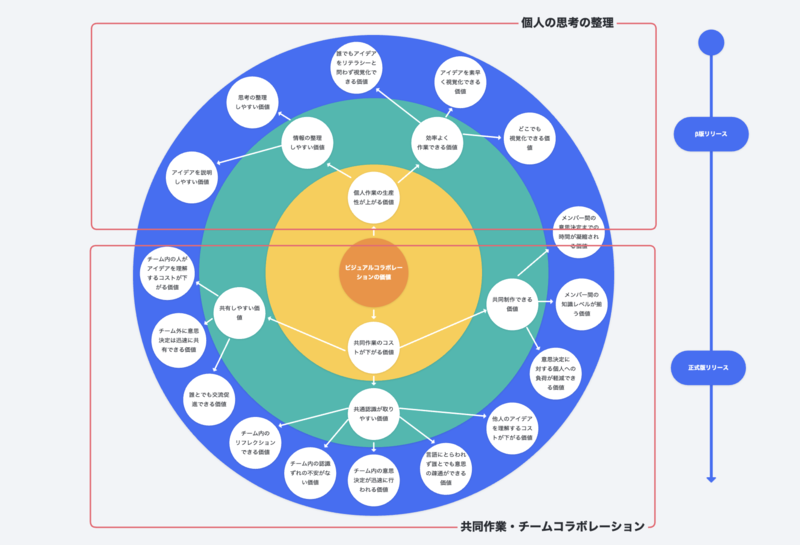
上半分が個人の思考の整理、下半分が共同作業やチームコラボレーションにおける価値となっています。
それではいよいよ、本題の「Layerの歴史で振り返る価値創出」についてお話しさせていただこうと思います。本日お話しする「Layer」という機能なのですが、上の価値マップにあった個人作業・共同作業のどちらにも価値のある重要な機能だったなと感じています。
整合性の担保を目指したLayer1.0
まず、先ほどから何度も出てくる「Layer」について一体どんな機能なのかを簡単にご紹介します。機能自体はいたってシンプルで、“最前面に移動”を選択すると緑色の付箋が最前面に移動する機能です。Strapではこのように“要素の重なり順を制御する仕組み”を「Layer」と呼んでいます。

それでは、このLayer機能を初めて実装した『Layer1.0』の話から振り返っていきたいと思います。この機能を実装するときに目標としていたことは“整合性を保った重なりの表現”です。データの不整合が起こることなく安全に更新できることや、データの更新量が一定量に抑えられるといったことを目標としていました。私たちはこの目標に対していくつか案を考え検討していったのですが、「Plan A」「Plan B」としてご紹介します。
Layer1.0 - Plan A:各Elementにindexを採番する
まず、最初に考えていたのは“各Element(Strap上に配置できる要素の総称)にindexを採番する”というPlan Aです。

各Elementにindexというフィールドを持たせて0,1,2と値を与え、重なりを表現できないかと考えました。この案は、考え方もデータ構造もすごくシンプルなところが良い点だったのですが、1度indexを更新するとデータ更新量が大きくなるという問題が出てきました。また、セキュリティルール(Firestoreのアクセス制御のデータ検証に利用できる制御構文)を利用してもindexの値の重複が防げないという問題があることが分かり、別案を考えることに。
Layer1.0 - Plan B:Layerの並び順を配列で持たせる
次に、“indexの代わりに配列で管理する”というPlan Bを検討しました。
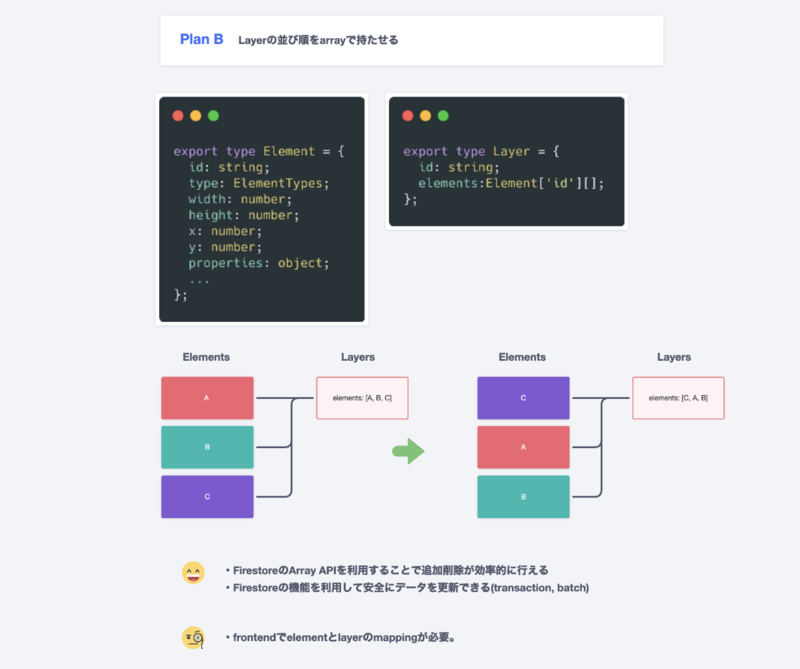
これは、Elementとは別にLayerというドキュメント(Firestore 上に保存するデータ単位)を用意して elementsという配列を用意する案です。 この案の良い点は、Firestore内にあるArray APIを利用することで追加や削除が効率的に行えるところです。また、Firestoreには他にもtransactionやbatchといった機能があり、これらを利用すると安全にデータが更新できるというところも。ただ、フロントエンドにおいてElementとLayerのデータが別れていることで生まれる複雑性については課題に感じていました。 様々な検討をし最終的には、 FirestoreのAPIを活用することで安全にデータ管理をできるPlan Bを採用することになりました。
社内での活用で見えた「同時編集」の課題
実際に実装したコードが、こちらです。
// 新規レイヤー追加時のarray api export const entityToSeedWithNewItems = ( items: Element['id'][], ): LayerDataDest => ({ elements: firebase.firestore.FieldValue.arrayUnion(...arrayCompact(items)), });
// 更新時の配列操作とトランザクション const localLayer = await layerSyncService.getLayer(id); // element Idをlayerの配列順に並べ替え const sortedIds = sortByIndex(elementIds, localLayer); const prevItems = localLayer.elements; const nextItems = swapElements(action, sortedIds, prevItems); if (equals(nextItems, prevItems)) return; const entity = { ...localLayer, elements: nextItems }; const prevSeed = entityToSeed(localLayer); const nextSeed = entityToSeed(entity); // Firestoreのトランザクション処理 layerSyncService.transactLayer(prevSeed, nextSeed, id);
まず新規Layerを追加するときにFirebaseのAPIを使って配列を追加しています。また、更新のときには配列操作を行った後にtransactionを使って更新する実装を行いました。
この実装によって、安全にデータを更新しながらElementの重なりを表現できるようになりました。しかし、β版として社内に提供したところ同時編集にまつわる問題が発生してしまいました。例えば、複数人が同時に編集したときにエラーが起きてしまったり、クライアント側に表示差分が発生してしまうことがありました。 ユーザー体験とは別に開発側では、Redo /Undoやグループ化といった機能を実装した際に少し作りが複雑になる可能性があることや、Firestoreのtransactionに頼っていたため更新速度が十分に出せないといった問題も起きていました。 これらの課題を解決するべく『Layer2.0』の開発が始まりました。
机上シミュレーションで共同作業を可能にしたLayer2.0
同時編集の問題はなかなか手元では再現がしづらく、問題が確実に解消するかは、ある程度実装してみないと判断が難しいため、私たちは机上シミュレーションを行うことにしました。こちらの図は、当時の検討プロセスです。
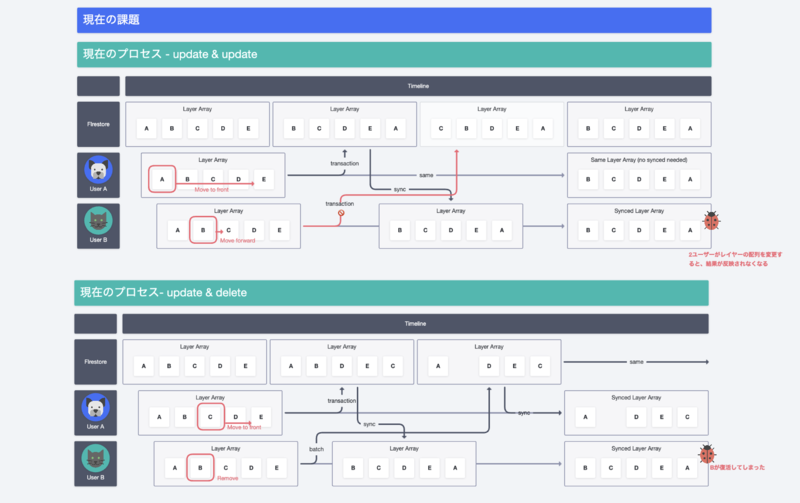
このように“複数人が配列を操作したときにどんな問題が起きるか”を検証しました。その結果、机上のシミュレーションだけでもデータ差分が出そうなことやデータが壊れそうということが分かりました。実際に分析した結果でも、同時に複数人が配列を操作することでエラーや反映差分が起きていることが判明したので、対策としてデータ設計・更新ロジックを刷新して配列をやめることを考えました。 実は、Firebaseの公式ブログに上記の用途で配列を使うのは良くないよと書いてあり、めちゃくちゃアンチパターンな設計をしていたことが分かりました(苦笑) 検証結果を踏まえて、上記の問題を解消するために行ったことを「Plan A」「Plan B」としてご紹介します。
Layer2.0 - Plan A:配列の代わりにオブジェクトを使う
Plan Aは“配列の代わりにオブジェクトを使う”という案でした。

オブジェクトを利用することにより、フロントエンド側でのデータ更新が少し簡単になることや、Layerの全体更新をすることなく配列のアイテムを1つずつ更新することができるという良い点がありそうでした。
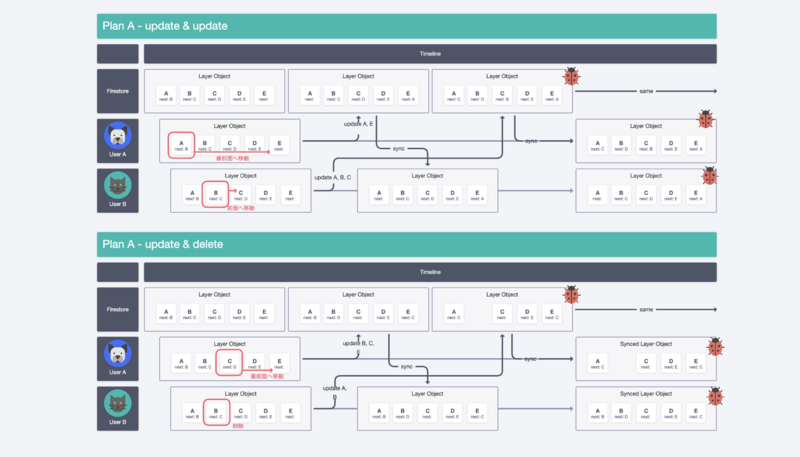
机上シミュレーションを行なった結果、想定よりも簡単に問題が起きてしまうことが分かりました。やっぱり1つのドキュメントを同時に編集すると問題が起きやすいんですね。
Layer2.0 - Plan B:Elementに対して1:1でLayerを持たせ、indexの間隔をあける
次に検討したPlan Bでは“Elementに対して1:1でLayerのデータを持たせ、index値の間隔をあける”という案です。間隔は、前回の0,1,2から1万2万と大きめに間隔をあけデータの重複を起きづらくしました。

Plan Bでも同様に机上シミュレーションを行い、問題が起きなさそうということが分かりました。Layerを変更したときに1つのドキュメントしか更新しないので、衝突が起きにくいことが分かり、Plan Bを採用することになりました。

Layer1.0からLayer2.0への変化
Layerデータの更新を例に、変更ポイントについてもご紹介します。
Before - 配列操作
const swapElements = ( action: LAYER_ACTIONS, target: Layer['elements'], source: Layer['elements'], ) => { switch (action) { case LAYER_ACTIONS.BRING_FORWARD: { const reversedTarget = [...target].reverse(); return swapToIndex(reversedTarget, source, 1); } case LAYER_ACTIONS.BRING_TO_FRONT: { const filteredIds = source.filter(id => !target.includes(id)); return filteredIds.concat(target); } ... default: { return source; } } };
After - indexをElementごとにアサイン
const maxInPrev = layers[layers.length - 1].index; const minInPrev = layers[0].index; switch (action) { case LAYER_ACTIONS.BRING_TO_FRONT: { const min = maxInPrev; const max = undefined; indexes = layersSyncService.createIndexes(prev.length, min, max); break; } case LAYER_ACTIONS.BRING_FORWARD: { indexes = prev.map(p => { const index = layers.indexOf(p); const min = layers[index + 1] ? layers[index + 1].index : maxInPrev; const max = layers[index + 2] && layers[index + 2].index; return layersSyncService.createIndexes(1, min, max)[0]; }); break; } ... } const next = prev.map((p, key) => { const entity = { ...p, index: indexes[key] }; const seed = entityToSeed(entity); layersSyncService.update(entity.id, seed); return entity; });
Layer1.0では、配列操作で前面に移動するという操作をしていました。それが Layer2.0では、indexをElementごとにアサインすることで変更するという形に。この変更によって、同時編集を行なってもエラーなくスムーズに共同作業ができるようになりました。 このようにとても良い結果の出たLayer2.0なのですが、その後ユーザーの増加や複雑な機能の追加というプロダクトの成長と共に新たな問題が顕在化してきました。 ということで、実はつい先日実装したばかりの『Layer3.0』の開発が始まります。
データ構造を刷新したLayer3.0
具体的にLayer2.0にはどんな問題があったのかというと、複雑な仕様のElementを追加・実装するたびに、Redo/Undoのようなデータ操作がどんどん複雑になってしまうことや、フロントエンド側のバグでElementにLayerが存在しない状態が発生してしまう点が問題としてありました。 これらの問題の原因についてはあたりがついており、作成・削除などのアクションで、ElementとLayerのどちらにも処理が必要なことを問題と考えていました。実は、Layer1.0の時代に懸念していた“ElementとLayerのデータが別れていることで生まれる複雑性”が顕在化してきたことになります。この対策として、LayerのindexをElementに統合することで簡素化しようと考えました。ちなみに、indexのロジックに関してはLayer2.0を運用していて大きな問題がなかったため、そのまま流用しています。
Layer3.0ではデータ構造にフォーカスし改善を実施していきました。改善した結果、データ構造はLayer1.0で考えていた構造になりました。シンプルに、LayerのindexをElementのindexへ移動してくるという構造です。

これにより、ElementとLayerを1:1で持たせていたものがElementだけのデータで良くなったため、データを大幅に削減することができました。しかしその反面、データ構造が大きく変わってしまいマイグレーション作業が必要になりました。正式リリース後初の長時間メンテナンスとなってしまったのですが、無事にリリースすることができました。
裏話!過去イチ大変だったマイグレーション作業
完全に余談ですが、このマイグレーション作業というのがなかなか大変な作業でした(笑) ユーザーが作成しているElement全てに適応する必要があったため、データ量がものすごく多くて、私たちがこれまで経験したことのないデータ量だったんです。そのため、実行に当たっては処理の効率化・時間配分の決定、CSチームとの連携などという事前準備もとても大変でした。実行段階でも、バックエンドに強いメンバーへ協力を仰ぎつつ処理を変え、改善しながら3,4回入念にテストを行いましたね。 無事にリリースできたときは「やっと完成形になったなぁ」という気持ちでした。実はこの対応で、他にも同時に更新できるElementの数が増えたり、パフォーマンスやコードが良くなったり色々と解消できたことがあって「やったね」という感じでした! 今回はユーザー側のデータを裏側で全部書き換えたのですが、今後はデータ構造に変更があっても、ユーザーが変更したタイミングで自動的にデータが新しいものに切り替わるようにして、一括で処理しなくても済むような状態にしていきたいです。
Layer2.0からLayer3.0への変化
Layer2.0から3.0でどのようにコードが変わったのかも、簡単にご紹介しておきます。 Layer2.0ではElementとLayerをそれぞれ操作していたのですが、Layer3.0ではElement作成とindexの決定を同時に行えるようになりました。
Before - Element, Layerをそれぞれ追加
entities.forEach(e => { const seed = entityToSeed(e); elementsSyncService.set(e.id, seed); }); const action = { type, payload: entities }; // Layerデータを別に追加 const layerAction = addLayersByElements(ADD_LAYERS, entities);
After - Element作成時にindexも付与
// Element作成とindex決定を同時に実施 const indexes = elementsSyncService.createIndexes(convertedElements); const entities = convertedElements.map((e, key) => { const entity = { ...e, index: indexes[key] }; const seed = entityToAddSeed(entity); elementsSyncService.set(e.id, seed); return entity; });
処理を簡素化することができましたし、コードの見通しも良くなりました。さらに、この対応によってデータ量も削減されボードの読み込みが30%ほど高速化しています。

これまでLayerの機能開発についてご紹介してきたのですが、実際に“ユーザーにはどんな価値があったのか”についてもお話ししたいと思います。冒頭で少し触れた『価値マップ』に戻ります。
Layer1.0~3.0が届けたユーザーへの価値
まず、Layer1.0です。

Layerの重なりの表現という、ビジュアルコラボレーションサービスとして基礎的な機能を実装しました。これによって“個人作業の生産性が上がる価値”を向上させることができたと考えています。
続いて、Layer2.0です。
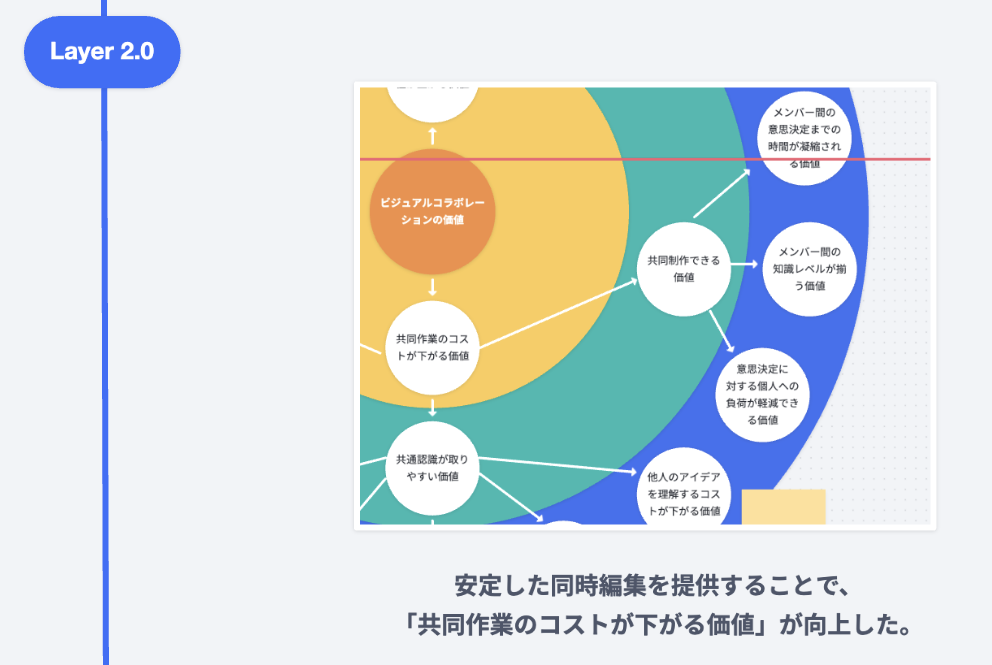
Layer2.0の時代には、安定した同時編集を提供できました。これによって“共同作業のコストが下がる価値”が向上したと考えています。
最後に、Layer3.0ですね。
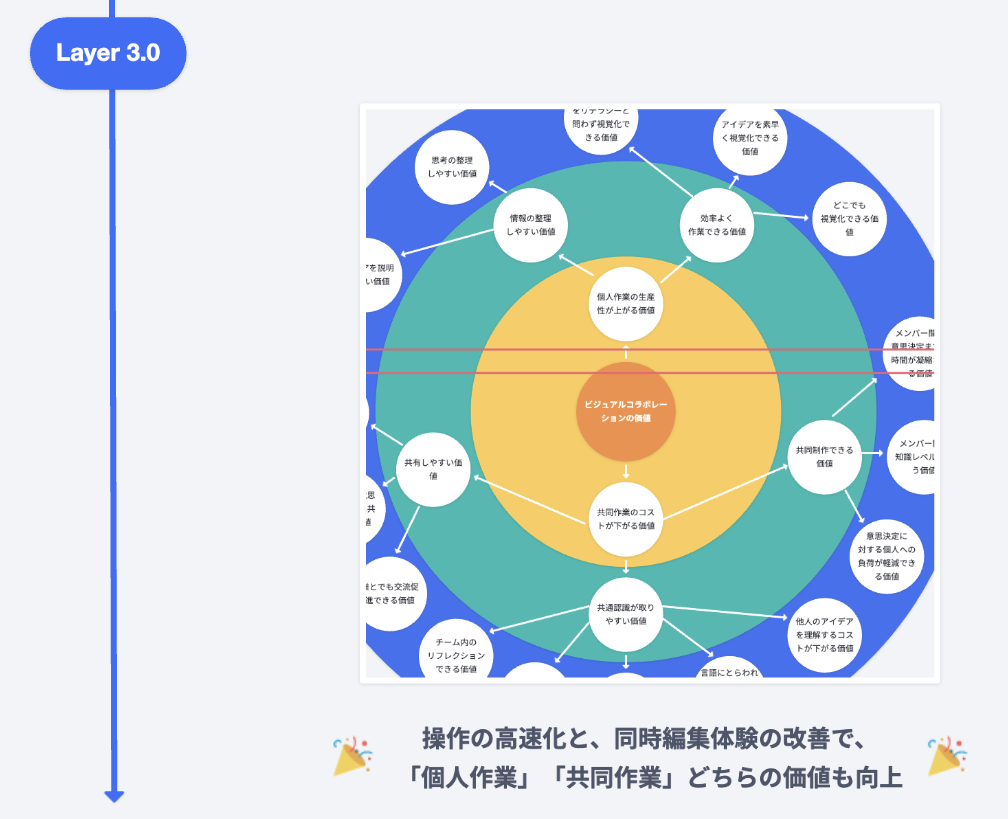
Layer3.0では、操作の高速化と同時編集体験の改善を行い、個人作業・共同作業のどちらの価値も向上したなと考えています。 このようにして、ユーザーにとってとても良い価値を段々と提供できた機能開発になったと感じています。実はそれだけではなく、この機能開発を通してチームとエンジニアにとっても良いことがあったんです。
体感した、ビジュアルコラボレーションの可能性
チームでは、Layer2.0の時代に行なっていた机上シミュレーションを通して“ビジュアルコラボレーションの価値”を体感することになりました。 今回の机上シミュレーションは、メンバーである黄さんがビジュアル化してくれたものをチームで共有しながら行ってみました。すると、メンバーの理解度や理解速度がとても上がったんです。開発の設計でも、文章ではなくビジュアル化する方が価値があると体感することができました。この開発をきっかけに今では、Strapを使って設計や仕様を共有することが当たり前になっています。 また、エンジニアとしては今後“機能開発が高速化する価値”を期待しています。Layer3.0の開発によって、コードがシンプルになり実装を簡素化することができました。今後、複雑な仕様のElementを実装しても手を加えやすくなっているのでは、と期待しています。
最後に
以上、「進化するフロントエンド2021 −4プロダクトから学ぶSPA/PWAの技術と実践−」での登壇内容をお届けしました。 このように私たちStrapチームは、継続的な機能改善を通してユーザーへ価値を届けていきたいと考えています。また、ユーザーの要望をそのまま改善するのではなく「実際にどういう課題があるのか」「それを解決するための方法や解決策は何なのか」と深掘っていくことで本当に最適なものを提供していきたいです。そして、そんな私たちの提供するStrapでユーザーの生産性が上がったり思考の整理の手助けができたりすると、とても嬉しいですね。
Strapチームではデザインの力を信じるエンジニアを募集しています。興味がある方はぜひこちらのリンクから気軽にご連絡ください。